
TLDR
Traditional test automation delivers fast initial coverage gains, then stalls. The reason is structural: static scripts depend on a stable environment, and production environments are not stable. This post explains why the stall happens, what drives it, and how agentic testing infrastructure handles the same conditions differently.
Introduction
Every QA team that has invested in test automation knows the pattern. Coverage climbs quickly in the first weeks. The scripts are fresh, the environment is clean, and the team is motivated. Then progress slows. Tests start failing for reasons unrelated to the code under test. Engineers spend more time fixing broken scripts than writing new ones. The coverage number stops moving.
This is not a team execution problem. It is a structural problem with how static automation tools work. Test automation coverage stalls because the tools are static and the environments they run in are not.
There are three approaches to test coverage, and each has a different cost curve. Manual testing is linear: it reaches full coverage eventually, but the cost scales with every new test case and every regression cycle. The team grows, the cost grows. Traditional automation buys speed early, then stalls at a coverage ceiling it cannot break through. Most teams hit this ceiling and never recover the momentum they had in the first weeks. The maintenance cost compounds as the suite grows, consuming the capacity that would otherwise go toward new coverage. Agentic testing reaches full coverage at a fraction of the spend because the agent handles environmental variation that static scripts cannot.
Understanding why the stall happens is the prerequisite for understanding what the cost difference actually comes from.
Why Traditional Automation Stalls: The Four Failure Modes
Static test scripts encode assumptions about the environment at the moment they were written. When those assumptions break, the test breaks. In a production environment, assumptions break constantly.
Random application behaviour is the first failure mode. Popups appear that were not in the test script. Race conditions cause elements to load in a different order. Timing-sensitive interactions fail intermittently. Each of these produces a test failure that has nothing to do with the feature under test. The engineer must investigate, determine the root cause, and update the script. Time that could go toward new coverage goes toward fixing what already exists.
Ops issues are the second failure mode. Database state leaks between test runs. External services flap. Test environments diverge from production over time. A script that passed last week fails today because something in the infrastructure changed. The test did not change. The environment did.
Configuration drift is the third failure mode. Over weeks and months, test environments accumulate small differences from each other and from production. Feature flags diverge. Dependency versions differ. What works in one environment fails in another. Tracking down environment-specific failures is expensive and often inconclusive.
Shared test infrastructure is the fourth failure mode. When multiple teams share test environments, contention creates unpredictable failures. Security updates lock down resources. Device pools run out. CI queues back up. None of these failures indicate a problem with the application. All of them consume QA engineering time.
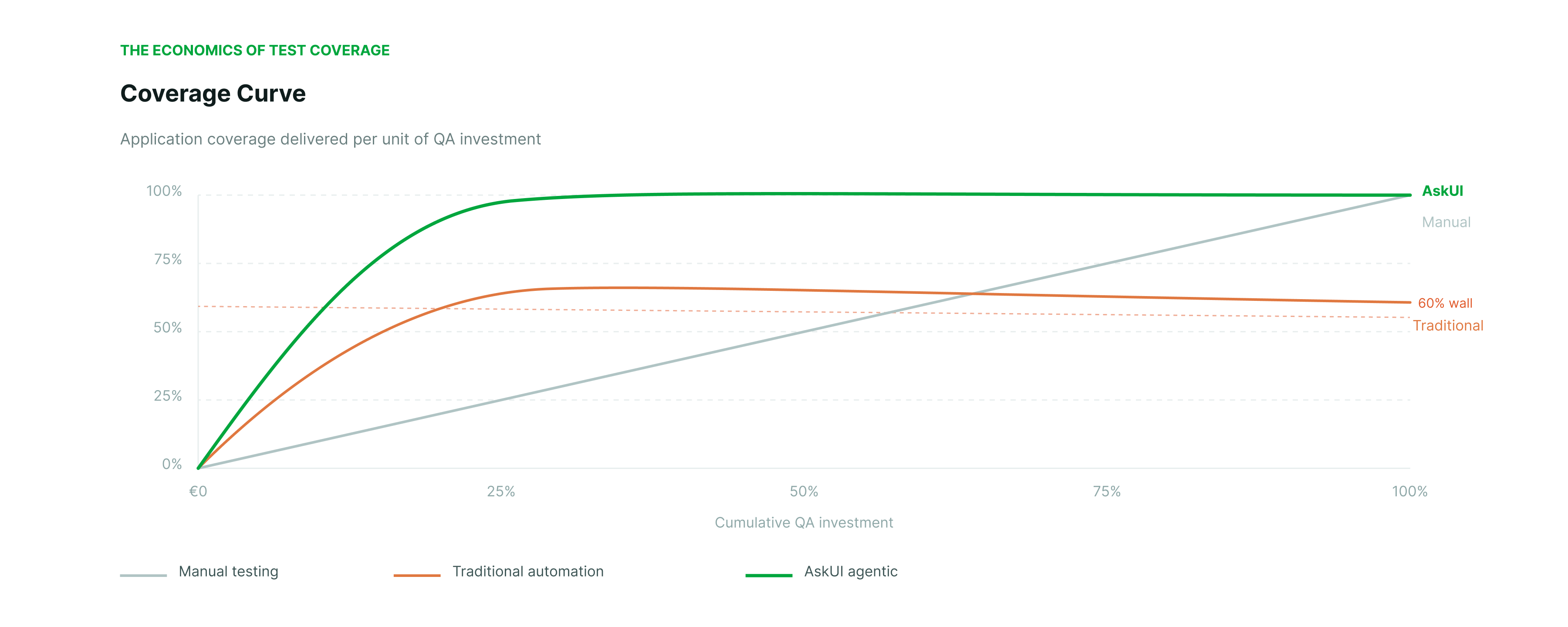
The result is a coverage ceiling. The team cannot push past it because the cost of maintaining existing coverage consumes the capacity that would otherwise go toward new coverage. The ceiling is not a fixed percentage. It varies by application complexity, team size, and infrastructure quality. But the pattern is consistent across organisations.
The economic consequence is that traditional automation delivers a poor return on QA investment past a certain point. The initial speed gains are real. The long-term cost of maintaining a large static suite often exceeds the cost of the manual testing it was meant to replace.
Why Manual Testing Does Not Scale Either
Manual testing reaches full coverage eventually. The problem is cost. Every new feature requires new test cases. Every release requires a full regression cycle. The cost scales linearly with the size of the application and the frequency of releases.
Teams that rely on manual testing hit a different kind of ceiling: headcount. You can always add more testers, but the cost of doing so grows with every product iteration. In a world where release cycles are measured in weeks rather than quarters, manual regression testing becomes the bottleneck that determines how fast the team can ship.
The comparison between manual and traditional automation is not about which is better in absolute terms. It is about where each approach delivers value. Manual testing remains essential for exploratory testing, edge case exploration, and scenarios that require human judgment. The problem is using it as the primary mechanism for regression coverage at scale.
The Throughput Problem: Stable Tests Over Time
Coverage percentage is one measure. Test stability is another, and it tells a different part of the story.
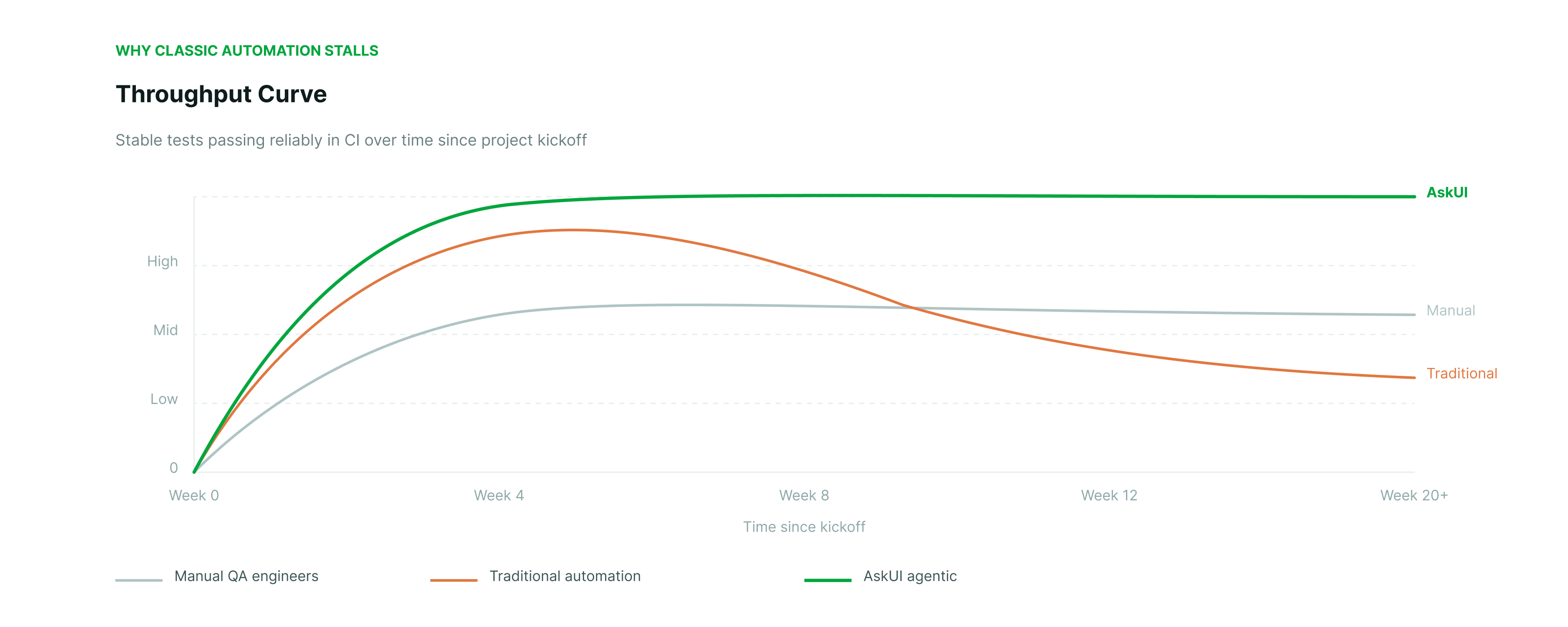
A test that fails intermittently provides no signal. Engineering teams learn to ignore flaky tests, which means those tests no longer contribute to quality assurance even if they are counted in the coverage percentage. Over time, as more tests become flaky, the effective coverage, meaning the coverage from tests that reliably produce meaningful results, declines even if the nominal coverage number stays the same.
The throughput problem is that static scripts lose reliability over time. In the first weeks after a test suite is written, most tests pass reliably. As the application evolves, as environments drift, as new edge cases appear, the percentage of reliably passing tests declines. A QA team running traditional automation typically has a significant portion of its test suite in a flaky or broken state, requiring constant maintenance to stay at the same nominal coverage level.
The engineering cost compounds. Every test added to a static suite is a future maintenance liability. The larger the suite, the more time goes to maintenance rather than new coverage. At some point, the suite becomes a burden rather than an asset.
What Agentic Testing Does Differently
The structural difference is how the agent handles environmental variation.
A static script treats an unexpected popup as a failure. An agentic testing agent treats it as part of the flow. The agent reads the current screen state, reasons about what is present, and decides how to proceed. If a cookie banner appears that was not there before, the agent handles it without a script update. If a loading indicator is slower than expected, the agent waits. The agent is not following a predetermined path. It is executing an intent.
This changes the maintenance economics. A static script must be updated every time the environment changes in a way that affects its predetermined path. An agentic agent adapts to environmental variation without script changes, because the script was never encoding the path in the first place.
The same principle applies to configuration drift and ops issues. The agent reads the current state of the screen, not the expected state encoded in a selector. If the environment has drifted, the agent works with what is actually there. The test result reflects the actual behaviour of the application, not a mismatch between the script's assumptions and the current environment.
For teams managing large test suites across multiple hardware variants or regional configurations, this changes the scalability equation. Adding a new variant does not mean writing a new suite. The same test instructions execute against the new variant. The execution layer handles the differences. This is what it means to scale your test projects like software.
How AskUI Fits
AskUI operates as an execution layer for agentic testing infrastructure. The ComputerAgent receives a natural language test instruction, and the LLM decides which tool to use for each action: selector, screen-based execution, shell command, CAN bus call, or API. The execution method is selected based on what the environment provides, not predetermined by the script.
On web environments where DOM and selectors are available, AskUI uses them. On embedded displays, industrial HMI panels, and locked-down production builds where no DOM exists, it uses screen-based execution. The same test instruction works across both environments. Engineers do not write different tests for different surfaces.
Execution caching addresses the throughput problem directly. The first run of a test records the full agent trajectory with LLM inference. Subsequent regression runs replay the cached trajectory at near-zero cost. When the UI changes, the agent detects the deviation during verification and makes a correction. The correction is logged. The test suite stays current without manual script updates.
For regulated industries where test evidence is a compliance requirement, every agent run produces a structured audit trail: what the agent saw, what it decided, what it did, and what the result was. This is generated automatically during execution, not assembled afterward.
AskUI is ISO 27001 certified, GDPR compliant, and deployable on-premise with zero model training on customer data. For automotive, medtech, and defense programs where data residency is a procurement requirement, this is not a differentiator. It is a prerequisite.
For a technical breakdown of how the execution layer and reasoning layer interact, see AskUI: Eyes and Hands of AI Agents. For how this applies in a regulated automotive context, see The Audit Trail: Verifiable Evidence for Automotive Compliance.
FAQ
Why does traditional test automation stall at a coverage ceiling?
Static scripts encode assumptions about the environment at the time they are written. As the application evolves, as environments drift, and as infrastructure introduces variability, those assumptions break. Maintaining existing coverage consumes the engineering capacity that would otherwise go toward new coverage. The ceiling is structural, not a function of team effort.
What is the difference between nominal coverage and effective coverage?
Nominal coverage counts the percentage of the application covered by tests. Effective coverage counts only the tests that reliably produce meaningful results. A flaky test that fails intermittently is counted in nominal coverage but contributes nothing to quality assurance. As static test suites age, the gap between nominal and effective coverage typically widens.
How does agentic testing handle environmental variation?
An agentic agent reads the current state of the screen and reasons about how to proceed based on what is actually present, not based on a predetermined path. Unexpected UI changes, popups, timing variations, and environment drift are handled as part of execution rather than treated as failures that require script updates.
Does agentic testing eliminate the need for test maintenance entirely?
No. When the application changes in ways that affect the expected output of a test, the test expectation must be updated. What agentic testing eliminates is the maintenance caused by environmental variation unrelated to the feature under test: broken selectors, timing failures, infrastructure issues, and environment drift. That category of maintenance is a significant portion of QA engineering time in mature static test suites.
How does execution caching affect regression test cost?
On the first run, the agent performs full LLM inference and records the trajectory. On subsequent runs, the cached trajectory is replayed without calling the LLM again. If the UI has changed, the agent detects the deviation and makes a correction. This means repeat regression runs cost a fraction of the initial run, making high-frequency regression testing economically viable at scale.