
One platform, every surface.
AgentOS runtime, a cloud LLM brain, and Hub for API keys, billing, and users, across desktop, web, mobile, embedded HMI, and physical devices.
One runtimeSoftware is stateful, and state breaks script-based test automation. Here's why coverage stalls at the maintenance wall, and how a computer-use agent resolves what selectors and scripts can't.
The more state a system carries, the harder scripts are to keep alive. Four kinds of state break test automation, and none of them are in the tester's control.
| State | What keeps changing | Why scripts break |
|---|---|---|
| Application state | New releases keep changing the UI | Selectors break; every fix needs a developer |
| Environment state | Eight teams change infra, data, and access | Flaky runs, QA locked out, hours spent finding the cause |
| Toolchain | Twelve tools and logins for one test cycle | Most of the day goes to navigating tools, not testing |
| Decay over time | State drifts and scripts rot | Coverage stalls at the 40–60% maintenance wall |
State isn't only in the app. Ops pushes updates, devs ship bugs, IT changes the network. Eight teams keep changing it, and every change can break a test.
Algorithmic automation can't absorb state, so coverage stalls at the 40–60% maintenance wall, and only manual effort carries the rest.
More testers don't help
More weeks don't help either
* Healthiness = passed / all tests. Failed = failed + broken + skipped.
One state out of sync and everything fails, and algorithms can't recover from errors.
One engineer rewrites the scripts while the team waits. State shifts again, the loop repeats.
Only manual testers cover above the wall. Each release demands more manual work.
Traditional QA resolves ambiguity through algorithms: selectors and code that only cover the fixed parts. A computer-use agent resolves it through intelligence: it sees the screen, reasons, and acts like a tester, so it absorbs state instead of breaking on it.
Deterministic selectors and scripted heuristics only cover a fixed slice of the screen. As instruction ambiguity and UI complexity grow, a computer-use agent keeps resolving, far past where scripts stall.
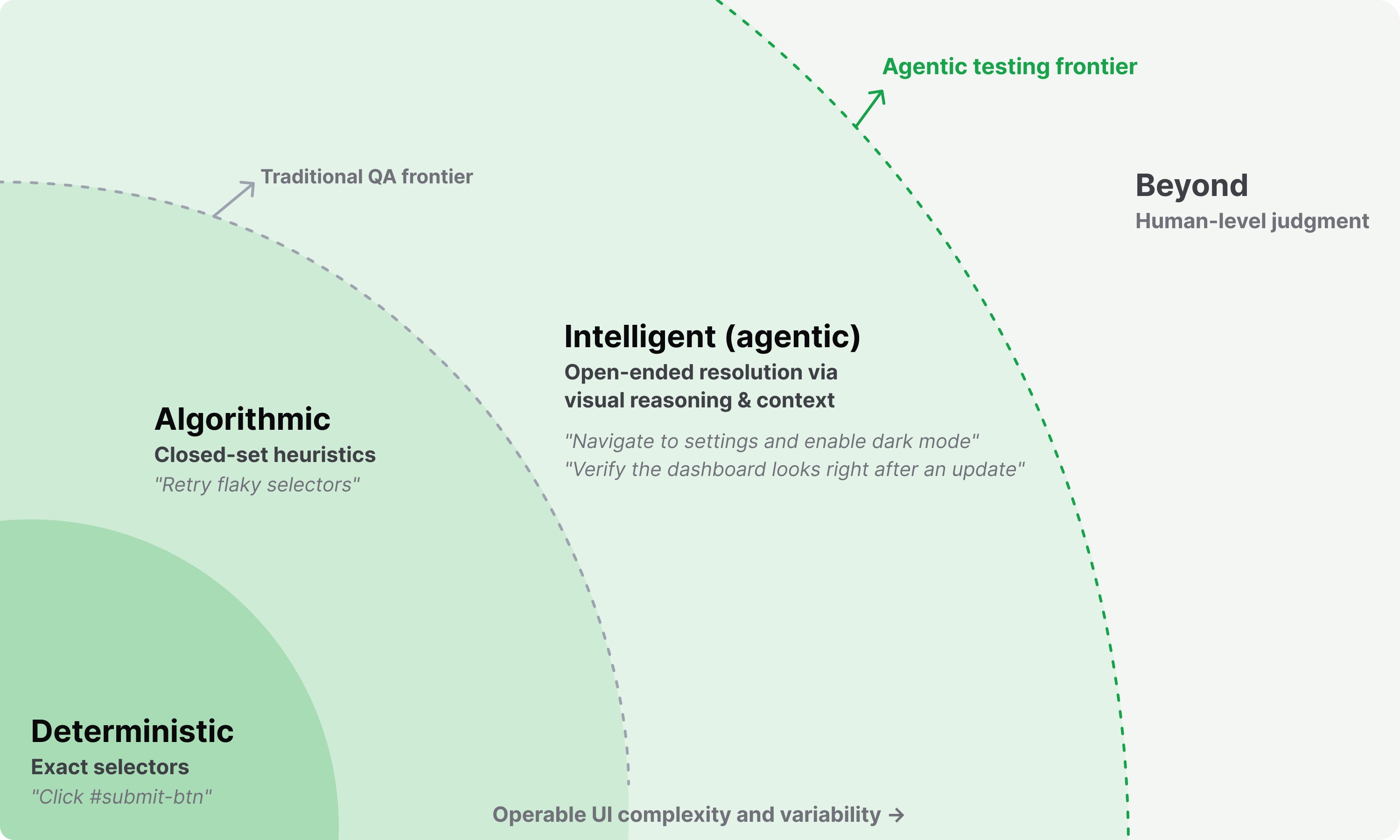
A computer-use agent works at the intelligence layer: it does everything deterministic and scripted tools do, and keeps going when the unexpected happens. Coverage is no longer capped at the wall.
With intelligence, coverage reaches 100%.
No translating requirements into selector code, no engineer in the loop. The natural-language requirement is the test: paste it in, and the agent reads it like a tester would.
Use existing test cases or write them in plain text. Either way the agent executes on the real UI and reports what it saw, and the same test survives the next UI change.
The same computer-use agent will also document and operate your interfaces: capture once, and a test, a work instruction, and an operation become interchangeable. More soon.
Plain language goes in. A cloud LLM is the brain; AgentOS is the runtime that drives any interface. Structured test results come back out: pass/fail, screenshots, and traces on every run.
The same computer-use agent, runtime, and workspace, wherever your interfaces and your tests live.
AgentOS runtime, a cloud LLM brain, and Hub for API keys, billing, and users, across desktop, web, mobile, embedded HMI, and physical devices.
One runtimeDomain experts author and review in plain text. No selectors, no brittle recordings.
No codeHost Mode installs on the target; Companion Mode drives locked-down and embedded screens via capture and input.
Host + CompanionOn-prem and air-gapped, ISO 27001, GDPR, BYOM, and machine-generated evidence on every run.
Compliance-readyDownload AgentOS, clone the demo project, or start with the SDK. Add API keys when you are ready to run agents.
Start for freeCommercial AgentOS, bring-your-own-model, and on-prem for distributed fleets. We'll map a plan to your stack.
Book a demo