
 YouYoung Seo
YouYoung Seo
Most teams that hit the limits of classical automation reach for the same solution.
They add AI.
A tool that generates test scripts automatically. A copilot that suggests fixes when selectors break. A layer of intelligence on top of the existing framework that promises to reduce maintenance overhead and extend coverage.
It helps. But it does not solve the problem.
Agentic testing resolves ambiguity through intelligence, not algorithms. Unlike AI-assisted testing tools that still produce deterministic scripts, computer-use agents (CUA) reason about instructions and interact with interfaces directly. That distinction matters more than most teams realize.
To understand why, it helps to look at where the real gap is.
The Test Case Nobody Could Automate
Consider this test case:
"Given I am logged in, when I complete the onboarding flow, then the dashboard should load correctly."A classical automation tool cannot execute this. There is no selector to click. No exact value to assert. The instruction is ambiguous by design , it describes an outcome, not a sequence of actions.
So the QA team rewrites it:
"Click #submit-btn. Assert text = 'OK'."Now it is automatable. But something has been lost. The original test case was asking whether the experience feels complete. The rewritten version is asking whether a specific button exists and a specific string appears.
These are not the same question.
This is the gap that AI-assisted testing was supposed to close. And it does, partially.
What AI-Assisted Testing Actually Does
AI-assisted testing tools operate on top of the existing automation architecture. They use machine learning to generate test scripts, suggest selector alternatives when elements change, and reduce the manual effort required to maintain a suite.
This is genuinely useful. Teams that adopt AI-assisted tools typically see faster script generation and lower maintenance overhead on the scenarios they were already automating.
But the underlying architecture has not changed.
AI-assisted tools still produce scripts. Those scripts still map actions to selectors and conditions. The output is still deterministic. It still operates within a closed set of anticipated scenarios.
The ambiguous test case is still out of reach. Because resolving that kind of ambiguity requires something scripts cannot provide: contextual judgment.
The Zone That Changes Everything
This is where the real shift happens.
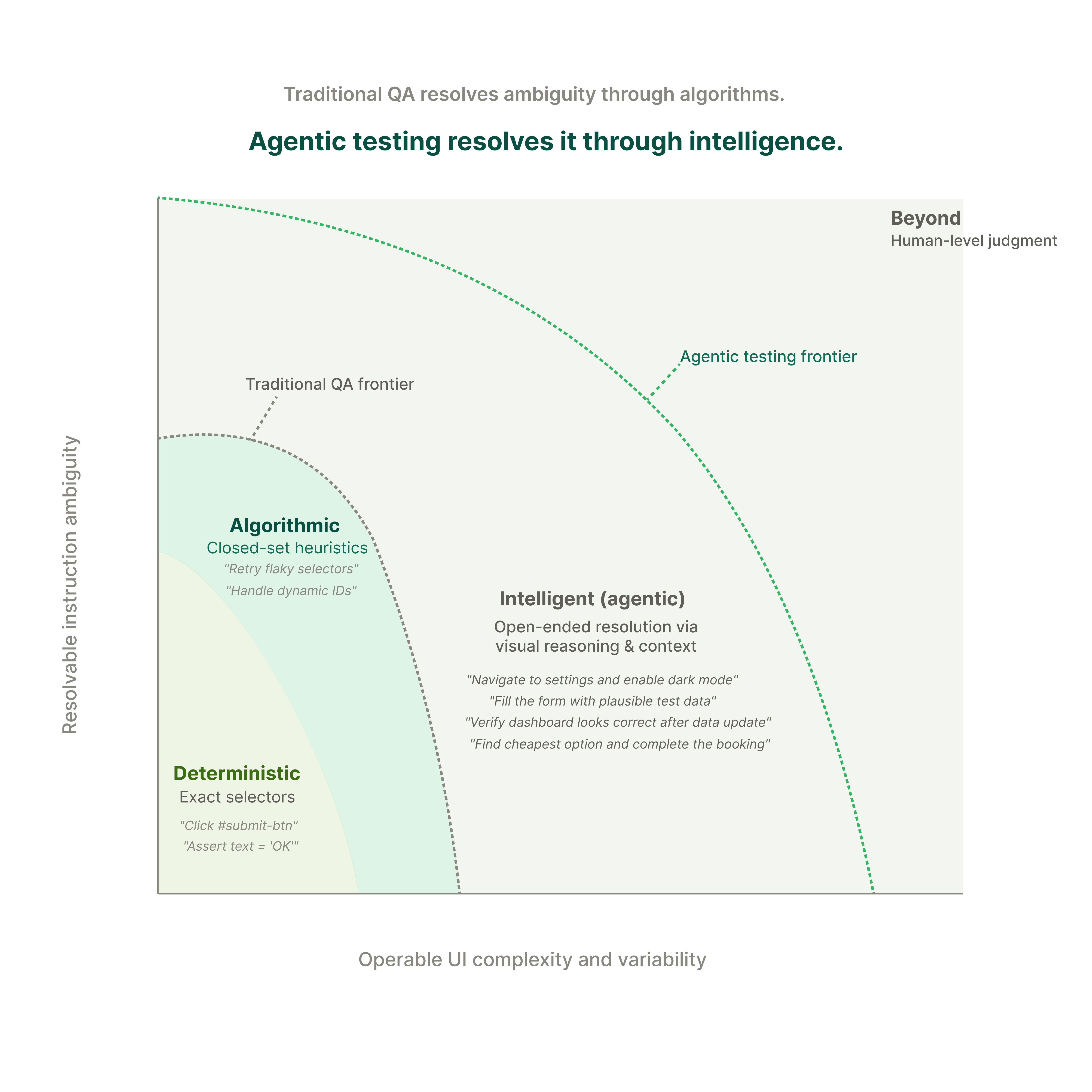 Look at the space between the Traditional QA Frontier and the Agentic Testing Frontier.
Look at the space between the Traditional QA Frontier and the Agentic Testing Frontier.
This is not a narrow gap. It is the majority of real-world testing: the instructions that require interpretation, the environments that have no accessible element structure, the scenarios that a human tester handles intuitively but a script cannot reach.
The examples in that zone are not exotic edge cases:
"Navigate to settings and enable dark mode."
"Fill the registration form with plausible test data."
"Verify the dashboard looks correct after the data update."
"Find the cheapest option and complete the booking."
Every one of these instructions is ambiguous. Every one requires contextual understanding. And every one is completely outside the reach of classical automation, including AI-assisted tools built on top of it.
Why Intelligence Is Different
The difference between AI-assisted testing and agentic testing is not a matter of degree. It is a matter of architecture.
AI-assisted tools augment deterministic systems. They make script writing faster and maintenance cheaper. But the execution model is the same: actions map to conditions, conditions map to selectors, selectors map to specific states of a specific interface.
Computer-use agents (CUA) do not execute scripts. They reason about instructions.
Given "fill the registration form with plausible test data", a computer-use agent does not look for a selector called #registration-form. It looks at the screen, understands what a registration form is, decides what plausible test data means in context, and completes the task.
This is the core difference. Traditional QA frameworks resolve ambiguity through algorithms, a closed-set approach. Agentic testing resolves it through intelligence, an open-ended approach that is more robust and generalizable across environments, interfaces, and instruction types.
The frontier has not moved slightly to the right. It has moved dramatically, covering a zone that most teams had simply stopped trying to automate.
What This Means for Your Test Coverage
The practical implication is significant.
Every test case your team rewrote to make it automatable, stripping out the contextual judgment, replacing outcome-based instructions with selector-based sequences, represents coverage that was lost in translation.
That coverage is now recoverable.
Not all of it. There is a zone beyond the agentic testing frontier where even intelligent agents cannot operate: instructions so ambiguous that no system can resolve them without further clarification. That boundary matters, and we will look at it in the next part of this series.
But the zone between the classical frontier and the agentic testing frontier is large. And for most teams, it contains exactly the test cases that have been handled manually for years, or not handled at all.
FAQ
What is the difference between AI-assisted testing and agentic testing?
AI-assisted testing uses machine learning to improve or accelerate the creation of deterministic test scripts. The execution model remains script-based. Agentic testing uses computer-use agents that reason about instructions and interact with interfaces directly, without requiring predefined selectors or scripts.
Can agentic testing agents replace classical test automation entirely?
No, and they are not designed to. Deterministic automation handles well-defined, stable test cases efficiently and reliably. Agentic testing extends coverage into the ambiguous zone that scripts cannot reach. The two approaches are complementary.
What kinds of instructions can computer-use agents handle that classical tools cannot?
Instructions that require contextual judgment: outcome-based test cases, natural language descriptions of expected behavior, tasks that involve navigating unfamiliar UI states, and testing in environments where no accessible element structure exists such as embedded plugin UIs or HMI displays.
Why does rewriting test cases to make them automatable lose coverage?
Because the rewrite trades outcome-based instructions for selector-based sequences. The original instruction asked whether something works correctly from a user perspective. The rewritten version asks whether specific elements exist in specific states. These are related but not identical questions.
The Boundary Is Further Than You Think
The agentic testing frontier is not a small extension of classical automation. It covers a fundamentally different class of test cases: the ones that require reasoning, not matching.
But there is a boundary. Instructions that are too ambiguous for any system to interpret. Scenarios where even human-level judgment requires more context than the test case provides.
In the final part of this series, we look at where that boundary sits, what it means for how teams write test cases, and what the shift from algorithmic to intelligent testing infrastructure looks like in practice.